排查问题2
本文共 355 字,大约阅读时间需要 1 分钟。
(1)增加到10个类

本次训练10个类,如上图,每类训练样本130个,测试结果如下:

(2)增加到11个类(+ 3 ),每个类130个样本
![]()


(3)在2的基础上,把4 其中一个字符改成 我们的测试数据,如下图中 z_0.jpg 。
![]()


(4)修改“4”,把干扰的4字体去掉

(5)修改“X”,把干扰的X字体去掉

(6)修改“T”,把干扰的X字体去掉

可以看出,第一个得分概率都非常小,得分小的,不靠谱。
(7)修改“Q”,把干扰的Q字体去掉

(8)修改“A”,把干扰的A字体去掉

(9)修改剩余数字,把干扰的数字字体去掉

此时,感觉,第一个字符“4”识别结果不可控了,可能因为本身“4”变形太大,目前的训练系统无法识别。下面将训练样本中一张“4”横向压扁,再次训练,结果如下,可以看到,得分最高的 ”A“,“X” .
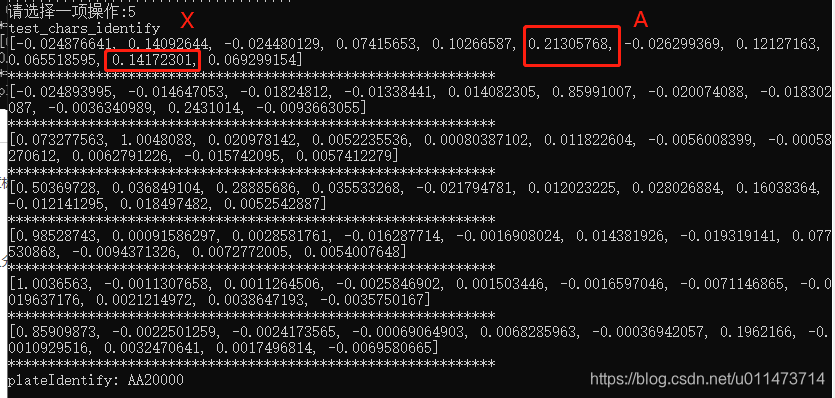

转载地址:http://bmsws.baihongyu.com/
你可能感兴趣的文章
vnpy学习_06回测结果可视化改进
查看>>
读书笔记_量化交易如何建立自己的算法交易01
查看>>
设计模式03_工厂
查看>>
设计模式04_抽象工厂
查看>>
设计模式05_单例
查看>>
设计模式06_原型
查看>>
设计模式07_建造者
查看>>
设计模式08_适配器
查看>>
设计模式09_代理模式
查看>>
设计模式10_桥接
查看>>
设计模式11_装饰器
查看>>
设计模式12_外观模式
查看>>
设计模式13_享元模式
查看>>
设计模式14_组合结构
查看>>
设计模式15_模板
查看>>
海龟交易法则01_玩风险的交易者
查看>>
CTA策略02_boll
查看>>
vnpy通过jqdatasdk初始化实时数据及历史数据下载
查看>>
设计模式19_状态
查看>>
设计模式20_观察者
查看>>